-
‰ًگح‰—p•ز
7. ƒJƒvƒ‰ƒ“ƒ}ƒCƒ„پ[–@پiKaplan-Meier method)‚ة‚و‚éƒCƒxƒ“ƒg”گ¶—¦‚ج“_گ„’è‚ئNumber at risk‚جژZڈo
‚±‚جƒTƒCƒg‚ح–³—؟‚ج“Œvƒ\ƒtƒg‚إ‚ ‚éپu‚qپv‚ً—p‚¢‚ؤ
ƒJƒvƒ‰ƒ“ƒ}ƒCƒ„پ[–@پiKaplan-Meier method)‚ة‚و‚éƒCƒxƒ“ƒg”گ¶—¦‚ج“_گ„’è‚ئNumber at risk‚جژZڈo‚ھژہچs‚إ‚«‚é‚و‚¤‚ةگà–¾‚µ‚½ƒTƒCƒg‚إ‚·پB
پu—صڈ°ˆم‚ج‚½‚ك‚ج‚qƒRƒ}ƒ“ƒ_پ[‚ة‚و‚éˆمٹw“Œv‰ًگحƒ}ƒjƒ…ƒAƒ‹پv‚ج“اژز‚ً‘خڈغ‚ةچىگ¬‚µ‚ؤ‚¨‚èپA–{ڈ‘‚ج“à—e‚ً—‰ً‚µ‚ؤ‚¢‚é‚à‚ج‚ئ‚µ‚ؤ‰ًگà‚µ‚ؤ‚¢‚«‚ـ‚·پB
ƒCƒxƒ“ƒg”گ¶—¦‚ج“_گ„’è
‚»‚ê‚إ‚ح‘پ‘¬‚â‚ء‚ؤ‚ف‚ـ‚µ‚ه‚¤پB
‚ـ‚¸‚حپu—صڈ°ˆم‚ج‚½‚ك‚جRƒRƒ}ƒ“ƒ_پ[‚ة‚و‚éˆمٹw“Œv‰ًگحƒ}ƒjƒ…ƒAƒ‹پv‚جp102ˆبچ~‚ًژQچl‚ة
—ûڈK—pƒfپ[ƒ^‚ً—p‚¢‚ؤ“œ”A•a‚ج—L–³‚ة‚و‚éگ¶‘¶—¦‚جˆل‚¢‚ًƒJƒvƒ‰ƒ“ƒ}ƒCƒ„پ[–@پiKaplan-Meier method)‚ً—p‚¢‚ؤ•`ڈo‚µ‚ؤ‚ف‚ؤ‰؛‚³‚¢پB
ژèڈ‡‚ةڈ]‚¢ژہچs‚·‚é‚ئRƒRƒ}ƒ“ƒ_پ[‚جƒXƒNƒٹƒvƒgƒEƒBƒ“ƒhƒE‚ة‚ح‰؛‹L‚ج‚و‚¤‚ة•\ژ¦‚³‚ê‚ـ‚·پB
.Survfit <- survfit(Surv(death_time, death_censor) ~ diabetes, conf.type="log", conf.int=0.95,
type="kaplan-meier", error="greenwood", data=practice)
.Survfit
plot(.Survfit, col=1:2, lty=1:2, conf.int=FALSE, mark.time=TRUE)
legend("bottomleft", legend=c("No","Yes"), title="diabetes", col=1:2, lty=1:2, bty="n")
quantile(.Survfit, quantiles=c(.25,.5,.75))
remove(.Survfit)
‚â‚邱‚ئ‚حˆê‚آ‚¾‚¯‚إ‚·پB
چإŒم‚ج
remove(.Survfit)‚جremove‚ًsummary‚ةڈ‘‚«ٹ·‚¦‚ؤ‰؛‚³‚¢پB
‚»‚µ‚ؤچؤ“xƒXƒNƒٹƒvƒg‚ًژہچs‚·‚é‚ئRƒRƒ}ƒ“ƒ_پ[‚جڈo—حƒEƒBƒ“ƒhƒE‰؛‹L‚ج‚و‚¤‚بŒ‹‰ت‚ھ“¾‚ç‚ê‚ـ‚·پB
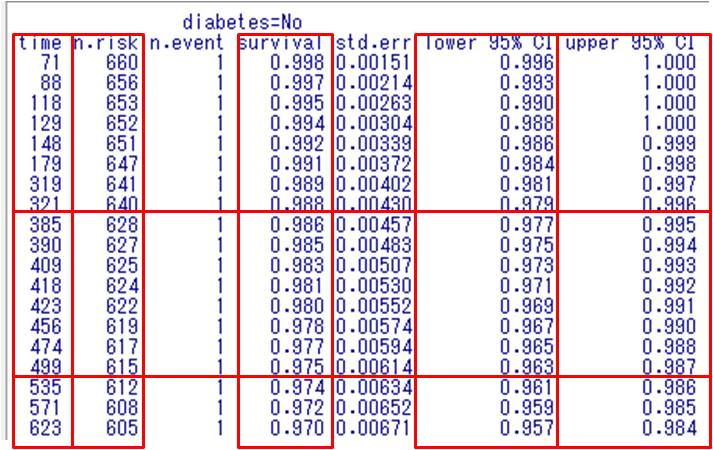
‚à‚¤‚¨‚ي‚©‚肾‚ئژv‚¢‚ـ‚·‚ھپA‚±‚جŒ‹‰ت‚ً‚ف‚é‚ئ‚ ‚éژ“_‚ة‚¨‚¯‚éگ„’èگ¶‘¶—¦‚ئ‚»‚ج95%گM—ٹ‹وٹشپAnumber at riskپiپپ‚»‚جژ“_‚إگ¶‘¶‚µ‚ؤ‚¢‚éٹ³ژز‚جگ”پj‚ھ‚·‚ׂؤ‚ي‚©‚è‚ـ‚·پB
‚»‚ê‚إ‚حڈع‚µ‚Œ©‚ؤچs‚«‚ـ‚µ‚ه‚¤پB
‚ـ‚¸‚±‚جƒfپ[ƒ^‚حƒ^ƒCƒgƒ‹‚ةdiabetes=No‚ئڈ‘‚¢‚ؤ‚ ‚邱‚ئ‚©‚ç“œ”A•a‚ج‚ب‚¢ٹ³ژز‚ة‚¨‚¯‚éƒfپ[ƒ^‚إ‚ ‚邱‚ئ‚ھ‚ي‚©‚è‚ـ‚·پB
ژں‚ةگشژlٹp‚إˆح‚ء‚½•”•ھ‚ًچ¶‚©‚猩‚ؤچs‚«‚ـ‚·پB
time‚حژ“_‚ًپAn.risk‚حnumber at riskپiپپ‚»‚جژ“_‚إگ¶‘¶‚µ‚ؤ‚¢‚éٹ³ژز‚جگ”پj‚ًپAsurvival‚حگ¶‘¶—¦‚ًپAlower 95%
CI‚ح‚»‚ج95%گM—ٹ‹وٹش‰؛Œہ’l‚ًپAupper 95% CI‚حڈمŒہ’l‚ًˆس–،‚µ‚ؤ‚¢‚ـ‚·پB
ژ€–S—¦‚ھ’m‚肽‚¢ڈêچ‡‚ح1‚©‚çگ¶‘¶—¦‚ًˆّ‚¢‚½’l‚ً—p‚¢‚ê‚خ‚و‚¢‚¾‚¯‚إ‚·پB
Number at risk‚جژZڈo
ژں‚ة”Cˆس‚ج“_‚ة‚¨‚¯‚éNumber at risk‚جژZڈo•û–@‚ةٹض‚µ‚ؤگà–¾’v‚µ‚ـ‚·پB
‚±‚جŒvژZ‚ة‚حggplot2‚ئsurvminerƒpƒbƒPپ[ƒW‚ً—p‚¢‚é‚ئ”ٌڈي‚ةٹب’P‚ةŒvژZ‰آ”\‚إ‚·پB
‚ـ‚¸‚ح‚±‚ê‚ç‚جƒpƒbƒPپ[ƒW‚ًƒCƒ“ƒXƒgپ[ƒ‹‚µ‚ؤ‰؛‚³‚¢پB
ژں‚ةˆب‰؛‚جƒXƒNƒٹƒvƒg‚ًR Console‚ة’£‚è•t‚¯‚ؤژہچs‚µ‚ـ‚·پB
‚±‚±‚إƒXƒNƒٹƒvƒg“àگآ•¶ژڑ•”•ھ‚جپu.Survfitپv‚حپAڈم‹L‚جƒJƒvƒ‰ƒ“ƒ}ƒCƒ„پ[–@پiKaplan-Meier method)‚إژہچs‚³‚ê‚éƒXƒNƒٹƒvƒg‚ج‚à‚ج‚ة‚ب‚è‚ـ‚·‚ج‚إپA•K‚¸ڈم‹L‚جremove‚ًsummary‚ةڈCگ³‚·‚éژèڈ‡‚ًچs‚ء‚½ڈم‚إˆب‰؛‚جƒXƒNƒٹƒvƒg‚ًژہچs‰؛‚³‚¢پB
break.time.by=‚جŒم‚جگ”ژڑ‚حپAژw’è“ْگ”‚²‚ئ‚جNumber at risk‚ھژZڈo‚³‚ê‚é‚ئ‚¢‚¤ˆس–،‚إ‚·‚ج‚إپA‹»–،‚ج‚ ‚éژ“_‚ًژw’è‚·‚ê‚خ”Cˆس‚جژ“_‚ة‚¨‚¯‚éNumber
at risk‚ًژZڈo‰آ”\‚إ‚·پB
#########ƒRƒsپ[ƒAƒ“ƒhƒyپ[ƒXƒg_‚±‚±‚©‚ç##########
library(ggplot2)
library(survminer)
ggsurvplot(.Survfit, break.time.by=365, risk.table=T)
#########ƒRƒsپ[ƒAƒ“ƒhƒyپ[ƒXƒg_‚±‚±‚ـ‚إ##########
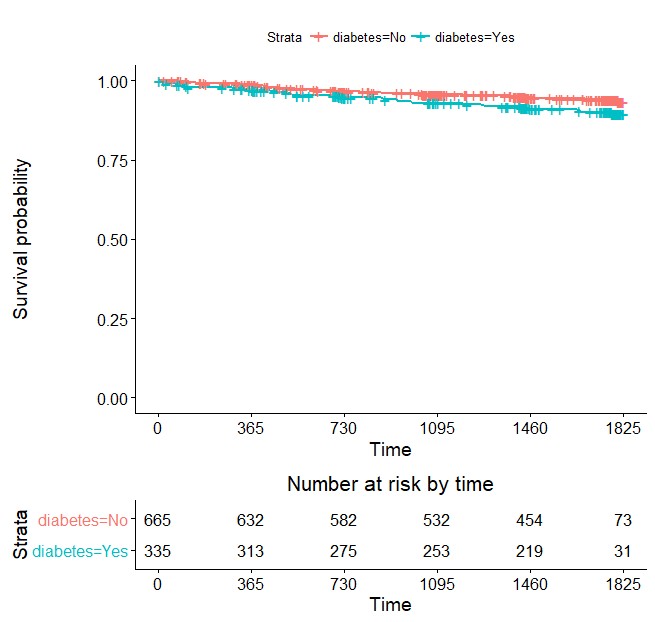
‚ب‚¨پAggsurvplot‚جƒپƒWƒƒپ[‚بaguments‚حˆب‰؛‚ج’ت‚è‚إ‚·پB
ƒRƒsپ[ƒAƒ“ƒhƒyپ[ƒXƒg‚µ‚ؤگFپX‚ئژژ‚µ‚ؤ‚ف‚é‚ئ–ت”’‚¢‚ئژv‚¢‚ـ‚·پB
ggsurvplot(.Survfit, col="red", palette=c("blue","green")
, censor=F, break.time.by=365, conf.int=T, risk.table=T
, linetype=1, pval=T, pval.coord=c(365, 0.80), size=1, fun="event",
ylim=c(0,1), xlim=c(0,1825))
1. col/palette
ŒQ•ھ‚¯‚ً‚µ‚ب‚¢ڈêچ‡‚حcol‚إپAŒQ•ھ‚¯‚ً‚·‚éڈêچ‡‚ة‚حpalette‚إگü‚جگF‚ًژw’肵‚ـ‚·پBگ”’l‚إ‚à•¶ژڑ‚إ‚à‚و‚¢‚إ‚·‚ھپA•¶ژڑ‚إژw’è‚·‚éڈêچ‡‚ة‚حƒNƒHپ[ƒeپ[ƒVƒ‡ƒ“‚إˆح‚ف‚ـ‚·پBŒQ•ھ‚¯‚·‚éڈêچ‡‚ة‚حpalette=c(1,2)‚âپApalette=c("blue","green")“™‚ئ‹Lچع‚µ‚ـ‚·پB
2. censor
FALSE‚إƒCƒxƒ“ƒgƒCƒ“ƒfƒBƒPپ[ƒ^پ[‚ًڈء‚µ‚ـ‚·پBTRUE‚إƒCƒxƒ“ƒgƒCƒ“ƒfƒBƒPپ[ƒ^پ[‚ً•\ژ¦‚µ‚ـ‚·پBFALSE‚حFپATRUE‚حT‚ئ‚ج‚فƒ^ƒCƒv‚µ‚ؤ‚à–â‘è‚ ‚è‚ـ‚¹‚ٌپB
3. break.time.by
xژ²‚جƒ}پ[ƒJپ[‚جˆت’u‚ًژw’肵‚ـ‚·پB
4. conf.int
95%گM—ٹ‹وٹش‚ًTRUE‚إ•\ژ¦پAFALSE‚إ”ٌ•\ژ¦‚ة‚µ‚ـ‚·پB
5. risk.table
Number at risk‚ًTRUE‚إ•\ژ¦پAFALSE‚إ”ٌ•\ژ¦‚ة‚µ‚ـ‚·پB
6. linetype
گü‚جƒ^ƒCƒv‚ًژw’肵‚ـ‚·پBگ”’l‚إ‚à•¶ژڑ‚إ‚à‚و‚¢‚إ‚·‚ھپA•¶ژڑ‚إژw’è‚·‚éڈêچ‡‚ة‚حƒNƒHپ[ƒeپ[ƒVƒ‡ƒ“‚إˆح‚ف‚ـ‚·پBŒQ•ھ‚¯‚·‚éڈêچ‡‚ة‚حlinetype=c(1,2)‚âپAlinetype=c("solid","dashed")“™‚ئ‹Lچع‚µ‚ـ‚·پB
7. pval
ŒQ•ھ‚¯‚·‚éچغ‚جƒچƒOƒ‰ƒ“ƒNŒں’è’l‚ً•\ژ¦‚µ‚ـ‚·پB
8. pval.coord
p’l‚ً•\‹L‚·‚éچہ•W‚ًpval.coord=c(365, 0.80)“™‚ج—l‚ةژw’肵‚ـ‚·پB( )“à‚جچإڈ‰‚جگ”ژڑ‚ھxژ²پAŒم‚جگ”ژڑ‚ھyژ²ڈم‚جچہ•W‚ة‚ب‚è‚ـ‚·پB
9. size
گü‚ج‘¾‚³‚ًژw’肵‚ـ‚·پB
10. fun
fun=NULL‚إˆê”ت“I‚بƒJƒvƒ‰ƒ“ƒ}ƒCƒ„پ[‹بگü‚ً•`ڈo‚µ‚ـ‚·پBfun="event"‚إ—فگدƒCƒxƒ“ƒg—¦‚ة•دٹ·‚µ‚ـ‚·پB
11. ylim/xlim
yژ²پA–”‚حxژ²‚ج”حˆح‚ًژw’肵‚ـ‚·پB